
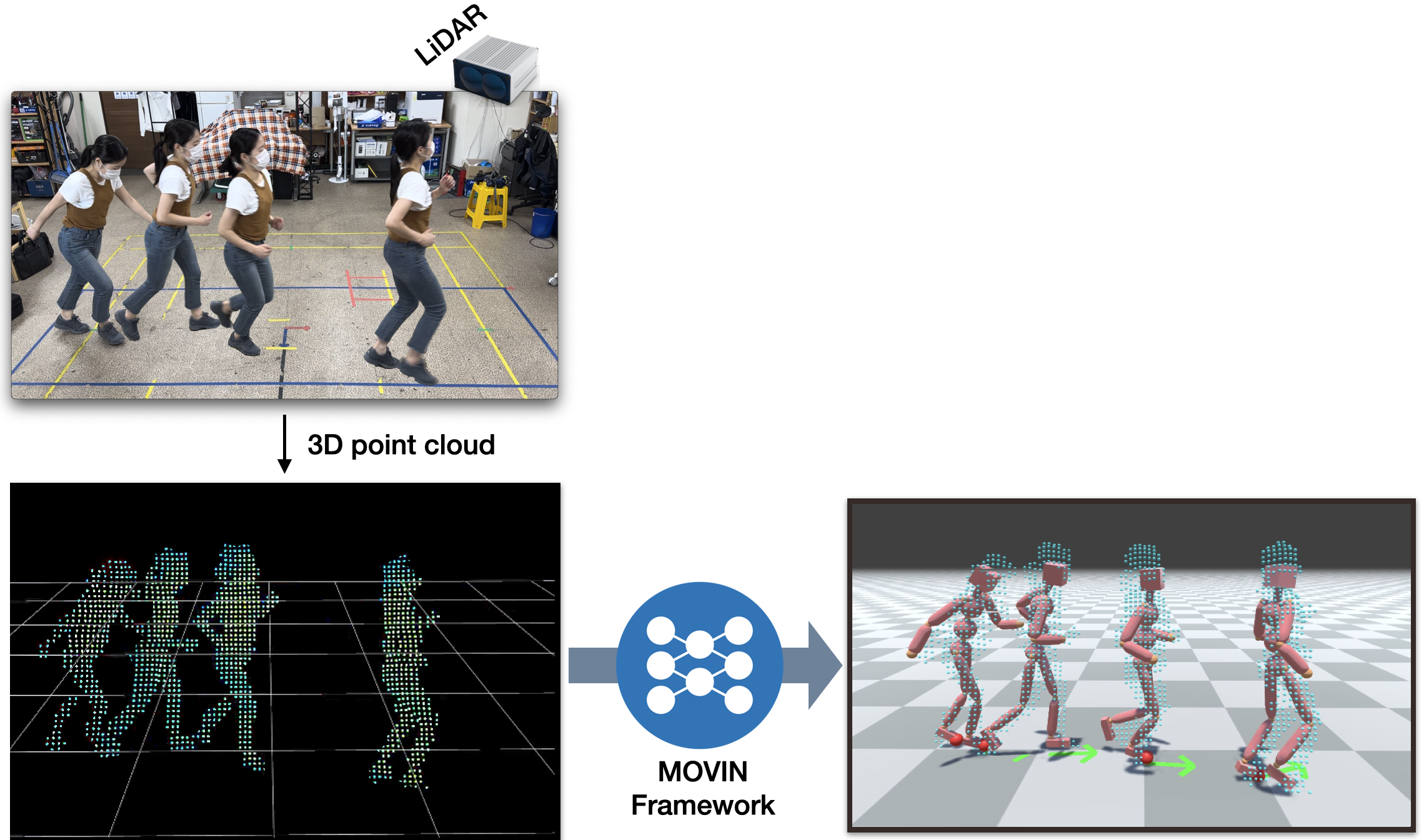
Recent advancements in technology have brought forth new forms of interactive applications, such as the social metaverse, where end users interact with each other through their virtual avatars. In such applications, precise full-body tracking is essential for an immersive experience and a sense of embodiment with the virtual avatar. However, current motion capture systems are not easily accessible to end users due to their high cost, the requirement for special skills to operate them, or the discomfort associated with wearable devices. In this paper, we present MOVIN, the data-driven generative method for real-time motion capture with global tracking, using a single LiDAR sensor. Our autoregressive conditional variational autoencoder (CVAE) model learns the distribution of pose variations conditioned on the given 3D point cloud from LiDAR.
As a central factor for high-accuracy motion capture, we propose a novel feature encoder to learn the correlation between the historical 3D point cloud data and global, local pose features, resulting in effective learning of the pose prior. Global pose features include root translation, rotation, and foot contacts, while local features comprise joint positions and rotations.
Subsequently, a pose generator takes into account the sampled latent variable along with the features from the previous frame to generate a plausible current pose. Our framework accurately predicts the performer's 3D global information and local joint details while effectively considering temporally coherent movements across frames. We demonstrate the effectiveness of our architecture through quantitative and qualitative evaluations, comparing it against state-of-the-art methods. Additionally, we implement a real-time application to showcase our method in real-world scenarios.
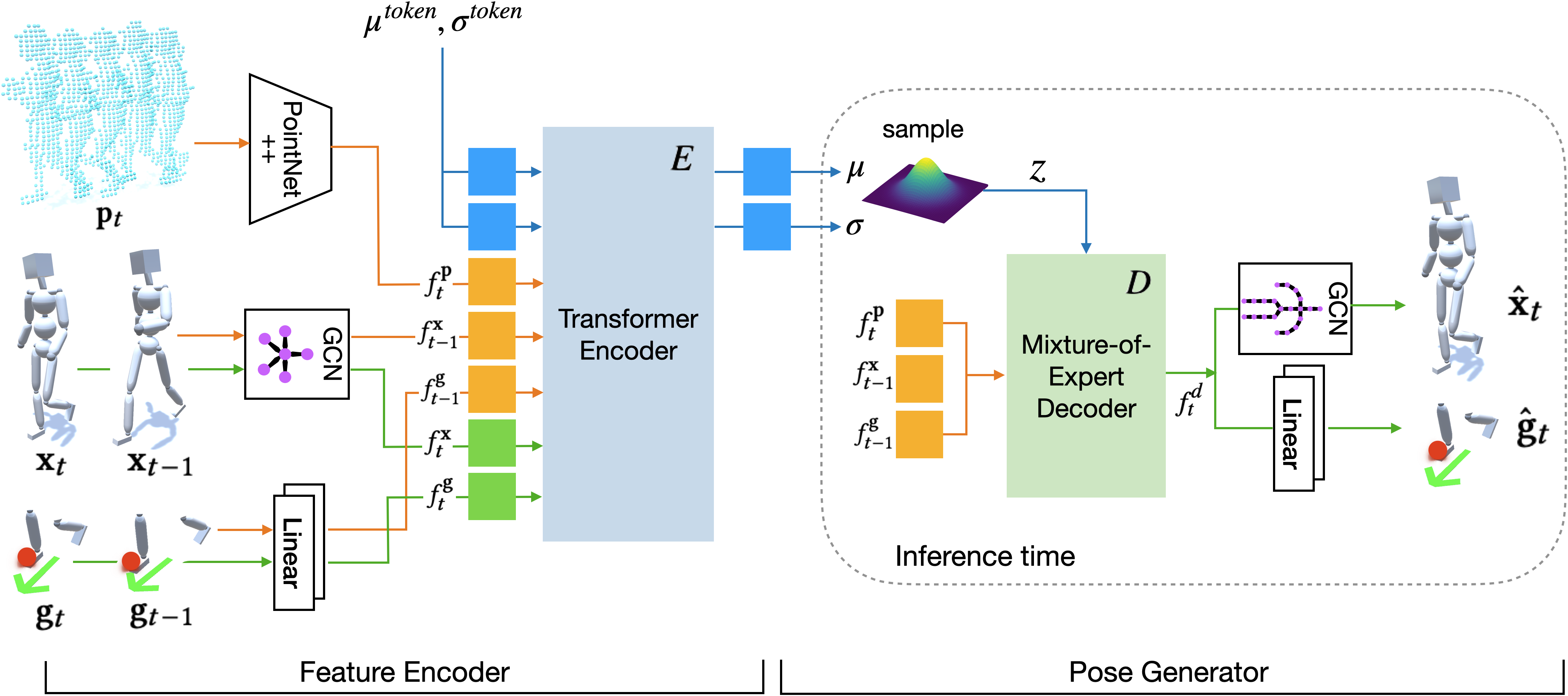
Overview of MOVIN framework. The model separates into the Feature Encoder and the Pose Generator. At inference time, only the Pose Generator and the embedding modules of Feature Encoder are used. Given the sampled point cloud sequence, our model generates current global and local pose features, which is used as a condition the next time frame.
Equipment setup for LiDAR based markerless real-time motion capture using our solution. We only need one laptop to process the incoming LiDAR signal and generate output motion aligned with the 3D point cloud data.
Users simply mount a single LiDAR sensor in front of themselves and can perform any action they desire.
Our real-time motion capture system with a single LiDAR. Our system does not require offline calibration and captures the subject’s motion in real-time, allowing users to check the results immediately.
To validate the effectiveness of our method, we compare our results with the state-of-the-art methods, VIBE and MotionBERT, which are vision-based methods. All results were not post-processed to ensure a fair comparison.
* Subject 1: 170cm
Locomotion.
Static.
* Subject 2: 162cm
Locomotion.
Static.
If you are interested in AI-powered markerless LiDAR based motion capture, check out our website, MOVIN, Inc.
@misc{jang2023movin,
title={MOVIN: Real-time Motion Capture using a Single LiDAR},
author={Deok-Kyeong Jang and Dongseok Yang and Deok-Yun Jang and Byeoli Choi and Taeil Jin and Sung-Hee Lee},
year={2023},
eprint={2309.09314},
archivePrefix={arXiv},
primaryClass={cs.GR}
}